 How have Yoobin?
How have Yoobin?

6주차에는 5주차에 이어서 딥러닝을 배우고, 3차 미니 프로젝트를 통해 머신러닝과 딥러닝을 직접 활용해보는 시간을 가졌다. 이번 미니프로젝트는 스마트폰 센서 기반 행동인식 분류를 하는 프로젝트였는데 좀 어려웠다.

🧠 Deep Learning
사실 딥 러닝은 배운 내용이 있어 조금은 마음이 편했고, 심지어 더 쉽게 가르쳐 주시는 것 같았다. 확실히 짧은 시간 내에 배워야 하고, 미니프로젝트에서 바로 써먹어야 하니 깊은 수학적인 배경은 설명해주지 않으신 듯 하지만, 그만큼 직관적으로 딥러닝 원리를 빠르게 이해할 수 있게 해주셨고, 실전에서 딥러닝 모델링 하는 법도 쉽게 가르쳐 주셨다. 처음 배울 때 들었던 강의가 train_step 따로 정의하고 넘파이 기반으로 수학적 원리를 설명해주는 강의라 아무리 친절하신 한기영 강사님이라도 어려울까봐 조금 긴장했었는데, 그것보다 훨씬 간단하게 실전에서 바로 써먹을 수 있는 압축 버전으로 가르쳐 주셨다.



자격증 시험 때문에 Tensorflow 관련 강의를 듣고 있었는데, 거기서 가르쳐주는 모델링 방식과 유사해서 시너지 효과가 났다.
multi-modal 모델을 어떻게 만드는지 (functional API), 시계열 모델링을 위한 데이터 전처리부터 모델링까지 그 과정이 잘 이해가 안되는 듯한 느낌이 있었는데, 강사님께서 간단하지만 알맹이 있게 알려주셨다. 한기영 강사님이 정말 잘 가르쳐 주시는게 간단하더라도 진짜 필요한 핵심만 쏙쏙 뽑아서 모델이 대충 어떤 원리고 어떤 흐름으로 작동하는지 쉽게 이해가 되도록 해주신다.

시계열 파트는 그렇게 깊게 가르쳐주지는 않으셨지만 따로 추가 공부할 수 있게 추가 자료도 주셨다.
(추가자료 좋아요.. 아니야 더 주지마세요.... 아니야 주세요....아니 주지마요.... 아니 주세요...)

강의 들으며 실습하다보니 어느 순간부터 모델 구조만 주어지면 손이 저절로 움직이는 나를 발견했다. 조금 익숙해지기 어려운 게 있다면 쓰고자하는 레이어 또는 메소드들이 어떤 라이브러리에 속하는지 외우는 것 정도...? 하지만 익숙해지기 시작하면, 대충 어디 라이브러리에 어떤 함수가 있는지 알게 되고, 그 뒤로는 그냥 능숙하게 모델링할 수 있게 된다.
3️⃣ 미니프로젝트 3차
📱 스마트폰 센서 데이터 기반 행동 인식 분류
1 ~ 2일차는 스마트폰 센서 데이터를 활용해 머신러닝과 딥러닝으로 행동 인식 분류를 하는 것을 목표로 진행되었다. 개인적으로 조금 어려웠던 것 같다. 데이터에 대한 이해와 도메인 지식을 깔고 가야 모델의 결과를 납득할 수 있을 것 같은데 feature 수부터 560개 정도여서 모든 feature에 대해 이해할 수가 없었다.
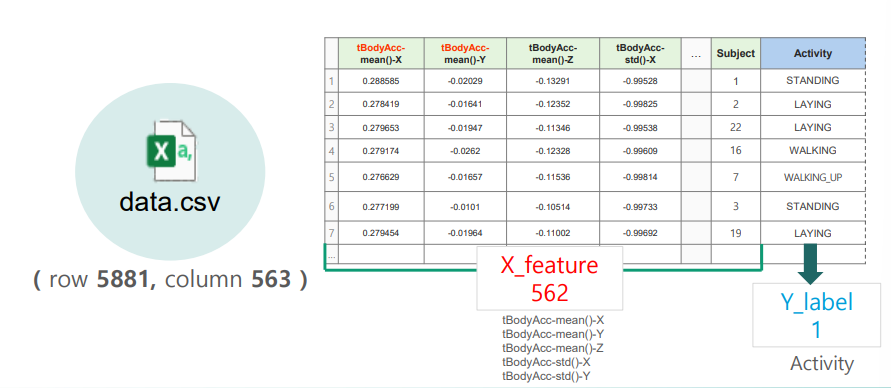
사실 모든 변수를 알아야 하는 게 아니라 몇 가지 특징들을 조합해서 변수들이 구성되기 때문에 그 몇 가지 특징들만 알면 됐었는데, 그게 gyroscope의 x축, y축, z축을 말하는 것이라 도통 직관적으로 이해하기가 힘들었다. 처음에는 이해하려고 스마트폰의 자이로 센서와 가속도 센서가 어떤 위치에 있고, 어느쪽이 z축을 향하는 것인지, 참여자들이 스마트폰을 어디에 어떻게 착용했는지 검색해봤으나, 이렇게 하나하나 뜯어본다고 해결될 것 같지 않았다.


그러다가 '이렇게 데이터를 직관적으로 이해하기 힘들기 때문에 머신러닝의 힘을 빌리는 것 아닐까?' 생각이 들었다. 그렇다고 차원이 많으면 과적합될 수 있으니 가이드 따라서 일단 해보기로 했다. (이렇게 생각했는데 나중에 모델링 단계에서는 딥러닝을 따로 사용하지 않았다.)

Random Forest로 변수 중요도를 뽑아서 팀원들과 비교해봤는데, 팀원들마다 다 다른 결과가 나와서 어떤 변수를 뽑아서 추합해야 하는지 정하기 난감했다. 팀원들이 변수중요도 데이터 프레임을 캡처해서 구글 슬라이드에 공유했는데, 변수 중요도가 높은 변수들이 제각기 달랐고, 순위도 다 달랐다...

그래도 나름 교집합을 찾아서 피클 파일로 저장하고, 그걸 기반으로 EDA를 수행했는데, 변수 중요도가 팀원들마다 다르니 '이걸 믿어도 되나...?' 싶은 생각이 들었다. 시간이 없으니까 의심은 뒤로하고 모델링을 하는데, 모델링도 행동을 정적/동적 행동으로 나눠 따로 예측한 뒤 합치는 작업을 해야 해서 휘몰아치듯 코드를 작성했다.

그리고 나중에 데이터 출처를 확인해봤을 때 센서 데이터이기도 하고, time-series라고 되어있는데 시계열로 안하나 조금 의아했었는데 캐글에서 뒤통수 맞을 줄이야ㅜㅜ. 데이터에 대해서는 이 정도만 파악하고, 시간이 부족할까봐 빠르게 빠르게 가이드만 따라서 했다.

의외로 놀라운 결과로 프로젝트를 마무리 할 수 있었다. 분류할 때는 굳이 딥러닝까지 갈 필요 없이 SVC, Random Forest, XGB 등의 머신러닝 알고리즘으로도 충분한 결과를 낼 수 있구나 느꼈다.
🏅 Kaggle Competition
3일차는 Kagglge Competition으로 진행되었다. 이번에도 '센서 데이터 기반 모션 분류'라길래 어제랑 비슷한 맥락일 줄 알았는데, 이번에는 시계열 딥러닝을 이용하는 게 포인트였던 것 같다. 어제처럼만 하면 된다고 생각해서 똑같이 머신러닝 분류 모델을 끝까지 고수해서 성능을 잘 내지 못했다.

솔직히 어제 time step이 있었는데 안 썼으니까 이번에도 안 써는 거겠지 생각하고 머신러닝 모델로 돌렸던 게 첫 번째로 성능을 내지 못한 큰 요인이었고, 두 번째는 중간 중간 time step은 있지만, 몇몇 변수들에 빠진 값들을 interpolate로 메꿔줘야 했던 걸 놓치고 무조건 빈 row는 drop했던 것이 큰 요인이었다.
1등 ~ 5등분들까지 발표를 하셨는데, 다른 분들 발표 들으면서, '왜 저걸 생각 못했지...' 생각이 계속 들었다. 1등하신분은 optuna를 이용한 튜닝까지 하셨었는데 이런 건 좀 배워야지 생각도 했다. 아 이럴 때 시계열 딥러닝 써보는 건데 써보질 못해서 너무 아쉬웠다... 어떻게 제출물 중에 샘플이 정확도가 제일 높을 수가... 앞으로는 모든 기본 모델링은 다 익숙해질 수 있도록 훈련을 해놔야겠다...
'Bootcamp > 2024 KT Aivle School' 카테고리의 다른 글
| [KT AIVLE School 5기] AI 개발자 트랙 8주차 후기 (0) | 2024.06.08 |
|---|---|
| [KT AIVLE School 5기] AI 개발자 트랙 7주차 후기 (0) | 2024.06.08 |
| [KT AIVLE School 5기] AI 개발자 트랙 5주차 후기 (0) | 2024.05.25 |
| [KT AIVLE School 5기] AI 개발자 트랙 4주차 후기 (0) | 2024.05.24 |
| [KT AIVLE School 5기] AI 개발자 트랙 3주차 후기 (0) | 2024.05.22 |