 How have Yoobin?
How have Yoobin?
0. Numpy란?

행렬이나 일반적으로 대규모 다차원 배열을 쉽게 처리할 수 있도록 지원하는 파이썬의 라이브러리
-Wikipedia
Numpy Notation
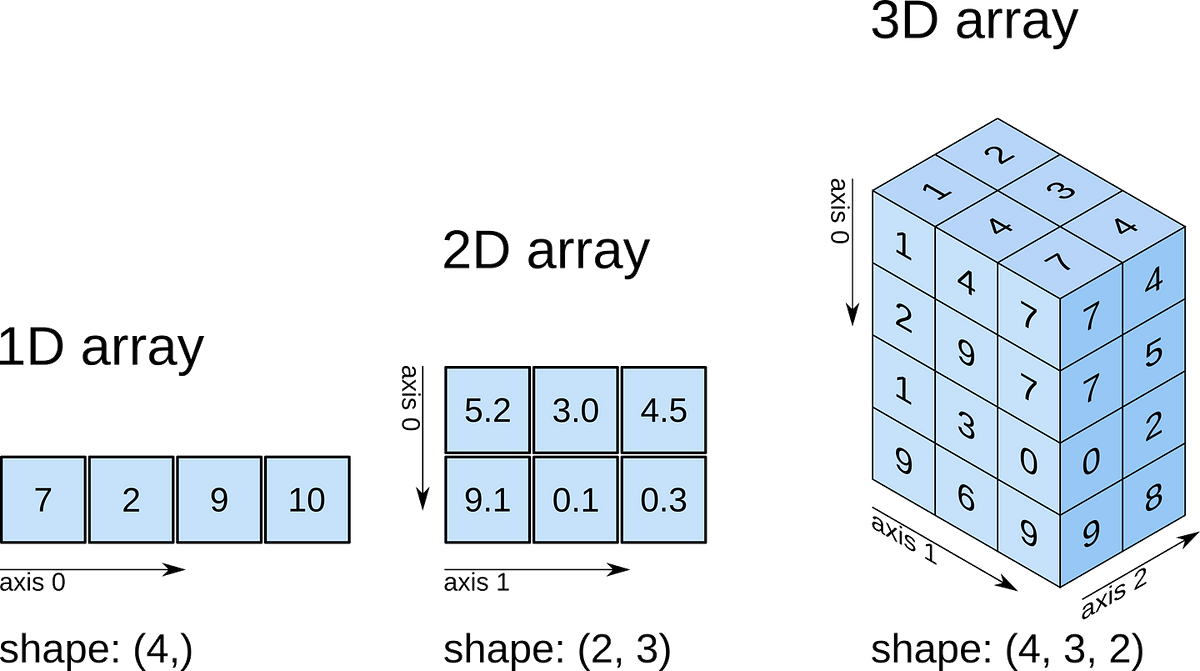
- axis : 배열의 각 축
- rank : 축(axis)의 개수
- shape : 축의 길이, 배열의 크기 (몇 행 몇 열인지)
- dimension : 차원 수
1. 라이브러리 불러오기
- numpy는
np라는 줄임말로 통용된다. 라이브러리를 불러와np라는 이름을 붙여주자. import numpy as np
2. Numpy 배열 만들기
np.array()함수를 이용하여 만든다.- 차원 수만큼 대괄호 쌍([])이 있다고 생각하면 된다.
1) 1차원 배열
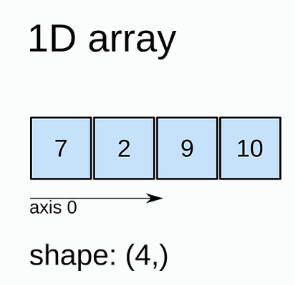
실행
a1 = np.array([7, 2, 9, 10])
# 확인
print(a1)결과
[7 2 9 10]2) 2차원 배열
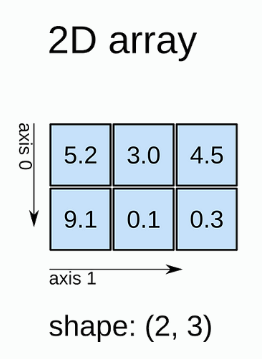
실행
a2 = np.array([[5.2, 3.0, 4.5],
[9.1, 0.1, 0.3]])
print(a2)결과
[[5.2 3.0 4.5]
[9.1 0.1 0.3]]3) 3차원 배열

실행
a3 = np.array([[[1, 4, 7],
[2, 9, 7],
[1, 3, 0],
[9, 6, 9]],
[[2, 3, 4],
[8, 1, 5],
[1, 3, 2]
[3, 5, 8]]])
print(a3)결과
[[[1 4 7]
[2 9 7]
[1 3 0]
[9 6 9]]
[[2 3 4]
[8 1 5]
[1 3 2]
[3 5 8]]]3. 배열 정보 확인
1) 차원 확인
array.ndim: 배열의 차원을 출력
실행
print(a1.ndim)
print(a2.ndim)
print(a3.ndim)결과
1
2
32) 크기 확인
array.shape:(행 개수, 열 개수 (,차원 개수))의 형태로 배열의 사이즈 반환, 각 숫자는 각 axis의 크기를 의미함
실행
print(a1.shape)
print(a2.shape)
print(a3.shape)결과
(4,)
(2, 3)
(4, 3, 2)3) 자료형 확인
array.dtype: 배열에 있는 요소들의 자료형 확인
실행
print(a1.dtype)
print(a2.dtype)
print(a3.dtype)결과
int32
float64
int324. 형태 변환하기
array.reshape(행 #, 열 #): 배열을 다양한 형태로 변환할 수 있다. 배열에 포함된 요소의 개수만 변하지 않는다면 다양하게 변환 가능
(e.g. (3,4) -> (2,6) -> (4, 3) -> (12, 1) -> (6, 2), 배열요소 12개)실행
실행
# 2 x 3의 배열 만들기
a = np.array([[1, 2, 3], [4, 5, 6]])
b = a.reshape(3, 2) # 2 X 3 -> 3 X 2
c = a.reshape(6) # 2 X 3 -> 1D array (6,)
print(b)
print(c)결과
[[1 2]
[3 4]
[5 6]]
[1 2 3 4 5 6]array.reshape(행 #, -1): 행의 개수만 지정하고 열 개수는 알아서 분배array.reshape(-1, 열 #): 열의 개수만 지정하고 행 개수는 알아서 분배
실행
a = np.array([[1, 2, 3], [4, 5, 6]])
print(a.reshape(1, -1)) # 행의 개수가 1개인 배열로 변환
print(a.reshape(-1, 3)) # 열의 개수가 3개인 배열로 변환결과
[[1 2 3 4 5 6]]
[[1 2]
[3 4]
[5 6]]5. Numpy 배열 요소 조회하기
# 다음의 배열에 있는 값들을 조회해보자.
a = np.array([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])1) Indexing
(1) 하나의 값 조회 (특정 열 & 행 조회)
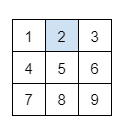
array[행,열,차원]: 특정한 위치의 하나의 요소 조회
실행
# 첫 번째 행, 두 번째 열의 요소 조회
a[[0],[1]]
print(a[0, 1])결과
array([2])
2(2) 특정 행 조회


array[행,:]or `array[행]`: 특정한 행에 있는 요소들 조회, 여러 개의 행을 조회하고 싶으면 숫자들을 리스트로 구성한 후 행에 준다.
실행
# 첫 번째 행 조회
print(a[0, :])
# 첫 번째, 두 번째 행 조회
print(a[[0, 1], :])
print(a[[0, 1]]) # 행 조회의 경우 ', :' 생략 가능결과
[1 2 3]
[[1 2 3]
[4 5 6]](3) 특정 열 조회


- `array[:, 열]` : 특정한 행에 있는 요소들 조회, 여러 개의 열을 조회하고 싶으면 숫자들을 리스트로 구성한 후 `열`에 준다.
실행
# 첫 번째 열 조회
print(a[: , 0])
# 첫 번째, 두 번째 열 조회
print(a[:, [0, 1]])결과
[[1]
[4]
[7]]
[[1 2]
[4 5]
[7 8]]2) Slicing
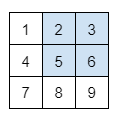
array[행1:행N, 열1:열N]: 찾고 싶은 2차원 배열을 조회, 마지막 값인행N과열N값은 포함되지 않는다.
실행
# 첫 번째 ~ 두 번째 행의 두 번째 ~ 세 번째 열 조회
print(a[0:3, 1:4])결과
[[2 3]
[5 6]]3) 조건 조회 (Boolean 방식)
array[조건]: 검색 조건에 맞는 요소만 선택
실행
# 모든 요소 중에서 5 초과인 것만 조회
print(a[a > 5])결과
[6 7 8 9]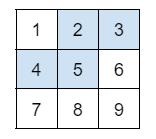
array[(조건1) & (조건2) & ...]: 조건을 모두 만족하는 요소만 선택
실행
# 모든 요소 중에서 2 이상 6 미만인 것만 조회
print(a[(a >= 2) & (a < 6)])결과
[2 3 4 5]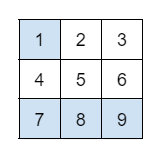
array[(조건1) | (조건2) | ...]: 조건중 하나라도 만족하는 요소 선택
실행
# 모든 요소 중에서 2 미만이거나 6 이상인 것 조회
print(a[(a >= 2) & (a < 6)])결과
[1 7 8 9]6. Numpy 배열 연산
1) 배열 사칙연산
x = np.array([[1, 2], [3, 4]])
y = np.array([[5, 6], [7, 8]])(1) 더하기
+ornp.add(array1, array2): 배열 더하기 (element-wise)
실행
print(x+y)
print(np.add(x,y))결과
[[ 6 8]
[10 12]](2) 빼기
-ornp.subtract(array1, array2): 배열 빼기 (element-wise)
실행
print(x - y)
print(np.subtract(x, y))결과
[[-4 -4]
[-4 -4]](3) 곱하기
*ornp.multiply(array1, array2): 배열 곱하기 (element-wise)
실행
print(x * y)
print(np.multiply(x, y))결과
[[ 5 12]
[21 32]](4) 나누기
/ornp.divide(array1, array2): 배열 나누기 (element-wise)
실행
print(x / y)
print(np.divide(x, y))결과
[[0.2 0.33333333]
[0.42857143 0.5 ]](5) 지수
**ornp.power(array, 지수): 지수 연산 (element-wise)
실행
print(x ** y)
print(np.power(x, y))결과
[[ 1 64]
[ 2187 65536]]2) 배열 통계
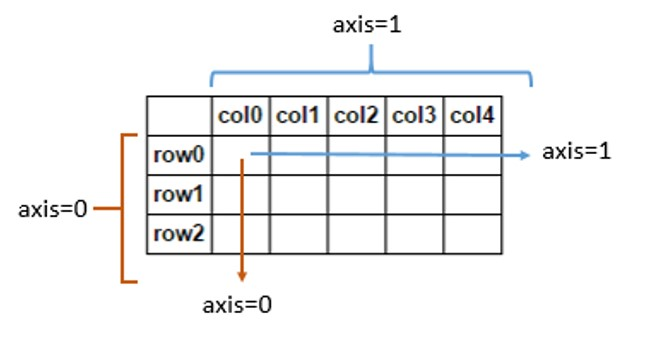
- 통계 메소드들은
axis옵션에 따라 열 기준으로 집계(axis = 0) 할 것인지 행 기준으로 집계 (axis = 1) 할 것인지로 나뉜다. 아무 옵션도 주지 않으면 자동으로 전체 집계를 한다.
# 다음의 배열에 대해 통계량을 구해보자
a = np.array([[1,5,7],[2,3,8]])
print(a)[[1 5 7]
[2 3 8]](1) 집계
np.sum(array, axis = ...)orarray.sum(axis = ...): 배열 집계
실행
# 전체 집계
print(np.sum(a))
# 열기준 집계
print(np.sum(a, axis = 0))
# 행기준 집계
print(np.sum(a, axis = 1))결과
26
[ 3 8 15]
[13 13](2) 평균
np.mean(array, axis = ...)orarray.mean(axis = ...): 배열 평균
(3) 표준편차
np.std(array, axis = ...)orarray.std(axis = ...): 배열 표준편차
(4) 최소/최대값
np.min(array, axis = ...)orarray.min(axis = ...): 배열 최소값np.max(array, axis = ...)orarray.max(axis = ...): 배열 최대값
7. 자주 사용되는 함수들
# 다음의 배열을 가지고 생각해보자.
[[1 5 7]
[2 3 8]]1) 최대/최소값의 인덱스 찾기
np.argmax(array, axis = ...)/np.argmin(array, axis = ...):array전체에서 최대값/최소값의 인덱스를 찾아준다. (axis옵션을 주지 않았을 때)axis = 0: 각 행에서의 최대값/최소값 인덱스를 반환axis = 1: 각 열에서의 최대값/최소값 인덱스를 반환
실행
# 전체 중에서 가장 큰 값의 인덱스
print(np.argmax(a))
# 행 방향 최대값의 인덱스
print(np.argmax(a, axis = 0))
# 열 방향 최대값의 인덱스
print(np.argmax(a, axis = 1))결과
5
[1 0 1]
[2 2]2) 조건에 해당하는 요소 처리
np.where(조건문, True일때 값, False일 때 값): 조건을 주고, 조건에 해당하지 않는 요소의 값과 조건에 해당하는 요소의 값을 지정한 값들로 바꿀 수 있다.
실행
# 2보다 큰 요소는 1, 같거나 작은 요소는 0으로 변환
np.where(a > 2, 1, 0)결과
array([[0 1 1]
[0 1 1]])

나... 기초적인거 정리하는 데에 시간을 너무 많이 들이고 있나...?
'Programming Language > Python' 카테고리의 다른 글
| [Python IDE] Jupyter Notebook 사용법 (3) | 2024.03.24 |
|---|